During the past half year, I’ve been asked many times about GDPR. The topic only gets hotter with every day the implementation date grows closer. In formulating an answer to these questions, I have been mindful about the risks of getting bogged down in rabbit-hole debates about attitudes and semantics. Instead, I have sought to share my experience and professional view in so far as it might be useful in a practical way for fellow IT architects, CTOs and CEOs. What follows is a summary of what I have found to be the most crucial points (links and references can be found behind the walls of words…)
To begin with a simple user-end experience, it isn’t difficult to identify with the feeling of being stalked by an ad via online sites and services, which are enabled by the personal databases they are sitting on. While it may still be an inconvenient truth for many, the simple fact is that marketing and sales companies are collecting / selling / giving away personal data for money or other reward, allowing commercial advertisers to recognise individual users anywhere and to hawk products and services based on users’ personal preferences.
The online social networks through which users publish and share their personal data continue to gain ground rapidly, both quantitatively (in terms of user numbers) and qualitatively (in terms of significance and impact). This document, for example, and this one clearly illuminate the extent to which digital life is driving demand for a new legal level of protection; indeed:
- 71% of EU citizens continue to say that providing personal information is an increasing part of modern life
- 50% of online Europeans use an online social network at least once a week
- 69% of people say their explicit approval should be required for 3rd party data sharing
- 30% of ad-blocker users are motivated by a fear of losing control
Sobering numbers, to be sure. Here’s another one: Facebook is, these days, valued at around $350 billion – a figure all the more astounding when you consider the company does not produce anything, does not fabricate anything. This perceived value is calculated by the data they are collecting and analysing. Whose data is this? The answer of course is: Yours; ours.
Even sitting on the top of the iceberg as architects and CEOs, we do feel the weight and appreciate the importance of the topic. Let’s be explicit: the overwhelming symbiosis of the real and the digital worlds has generated a not-so-new but pressing challenge: privacy protection. And the previous policy of kicking the can down the road has only made the challenges more pressing and acute than ever.
That’s not to say that this topic was not always present in strong arguments during speeches and presentations, it’s just that IT usually found the cheapest way at code level to keep the developers’ playground as insulated as possible. IT was effectively preserved as a field in which ’external’ legal or social concerns should not interfere.
Privacy protection of course can and should be considered as a legal question as much as a technical one. However, we can’t and shouldn’t hide from the moral aspect: the decision about adopting privacy protection cannot and should not take place exclusively inside a techno-legal vacuum. Ultimately, as IT leaders, we have to remind ourselves what technology is for: to serve people and not to work against them.
So as IT leaders, we do have an inescapable responsibility to the real world outside our immediate technical remits.
The 'tech revolution' has until now enjoyed - and sought to prolong - a kind of 'honeymoon period', insulated from the real world of responsibility regarding all kinds of things from privacy to censorship. With all of the big players recently in the media spotlight, it can be said without doubt that reality is starting to bite.
GDPR
In 2016, the EU made the bravest public-led technological effort I have seen – the GDPR: a tough, strict regulation, focused on data privacy.
GDPR as a standard declares, that data protection is indeed a fundamental human right; individuals have the right to protect their data; one’s personal data is fundamentally one’s own.
Essential force of the regulation:
Affected: all companies based in the EU or handling / targeting the personal data of EU citizens must comply.
Enters into force: 25th May of 2018.
Liability/risk: €20 million or 4% of global annual turnover for the preceding financial year
I don’t assume any legal expertise regarding the standard: I do recommend the great points made already here here and here.
And I strongly advise reading this great summary by ico.org.uk
I will add some general, practical conclusions related to immediate impact:
- The EU have levelled the legal aspect to the DB storage layer, with profound effects on architecture level, DB management level, devops level and on company culture level for sure.
- New roles will appear (DPO, Controller) while developers and devops will lose many controls…
- GDPR requires the protection of data from external and internal threats, meaning that serious measures need to be introduced into company culture and processes to comply with the regulation.
Of course, even with such a bold and far-reaching standard, IT leaders will retain a degree of liberty to bend the reality, to shape interpretations, to soften meanings to the level of nice diagrams and ends/means arguments, but we have a choice of prominence here, and the prominence we can give is a respectful approach towards the very spirit this regulation proclaims: that technology should serve the people.
This does require the acceptance that a primarily moral obligation cannot be measured in gold coins, even if the implication of the regulation on IT or company culture seems severe.
When it comes to privacy, there has always been a gulf between practice and presentation. To give an anecdotal example, I once worked for a bank where the production DB (with balance information) was readable / writable by some of the developers. At the same time, the company was in possession of all security badges and certifications possible. This won’t surprise too many people in IT but for the non-IT world this kind of discrepancy is shocking and erodes trust in what we do. It’s in a large part because of everyday discrepancies like this that the GDPR has come into being.
I am not qualified to speak in legal terms but as a chief architect I’ve spent many, many hours with legal professionals, trying to find the right way rather than the makeshift way – all too often on cheap and seedy backroads. Implementation requires even greater vigilance: here is rather a swampy no-mans-land than a road; It’s necessary to discover all manner of traps and potential detours in order to deploy a GDPR-compliant data storage solution – in a manner of course, that avoids sabotaging the current flows and development culture in place. Some disruption/change is unavoidable:
- Yes, the physical DB separation of the (sensitive) personal data is inevitable
- Yes, data flow, data management processes have to be redesigned
- Yes, DB encryption on production will make the data unreadable to devops and developers
- Yes, developers lose the all “admin” power on personal data. They will get only minimised and psdueonimised data.
As this should make clear, hard decisions need to be made on all IT levels. Though the challenge may be daunting, and the cheap shortcuts tempting, full-compliance is eminently do-able: GDPR can be made as it has been defined – and I can provide a real example.
After several months of orchestration and engineering, we succeeded in creating a ready-to-deploy blackbox product, allowing our client to introduce the “individual rights”, “accountability”, “security” and “data transfer” of GDPR without any serious human effort or temporal investment, and with an integration window of just a few weeks.
Before I explain the basics of how we achieved this and the practical issues involved, I want to acknowledge that with this shiny new data protection issue, there are naturally more questions around the scenarios of enforcement, breach notification and authorities than there are answers. I don’t claim or even aim to provide answers to every one of these questions, or even to know what all the questions are: it should be stressed that this is new and evolving territory. As I mentioned from the outset, this presentation is intended to be summarial and practical – in-depth theoretical reasoning and exhaustive investigation of these aspects is something I leave for another day, following the publication of more specific documents…
WHERE WE BEGAN
GDPR introduces new roles and processes to facilitate the space where privacy can prevail. Let’s use the following diagram as a possible solution for the GDPR data-flow for a general enterprise:
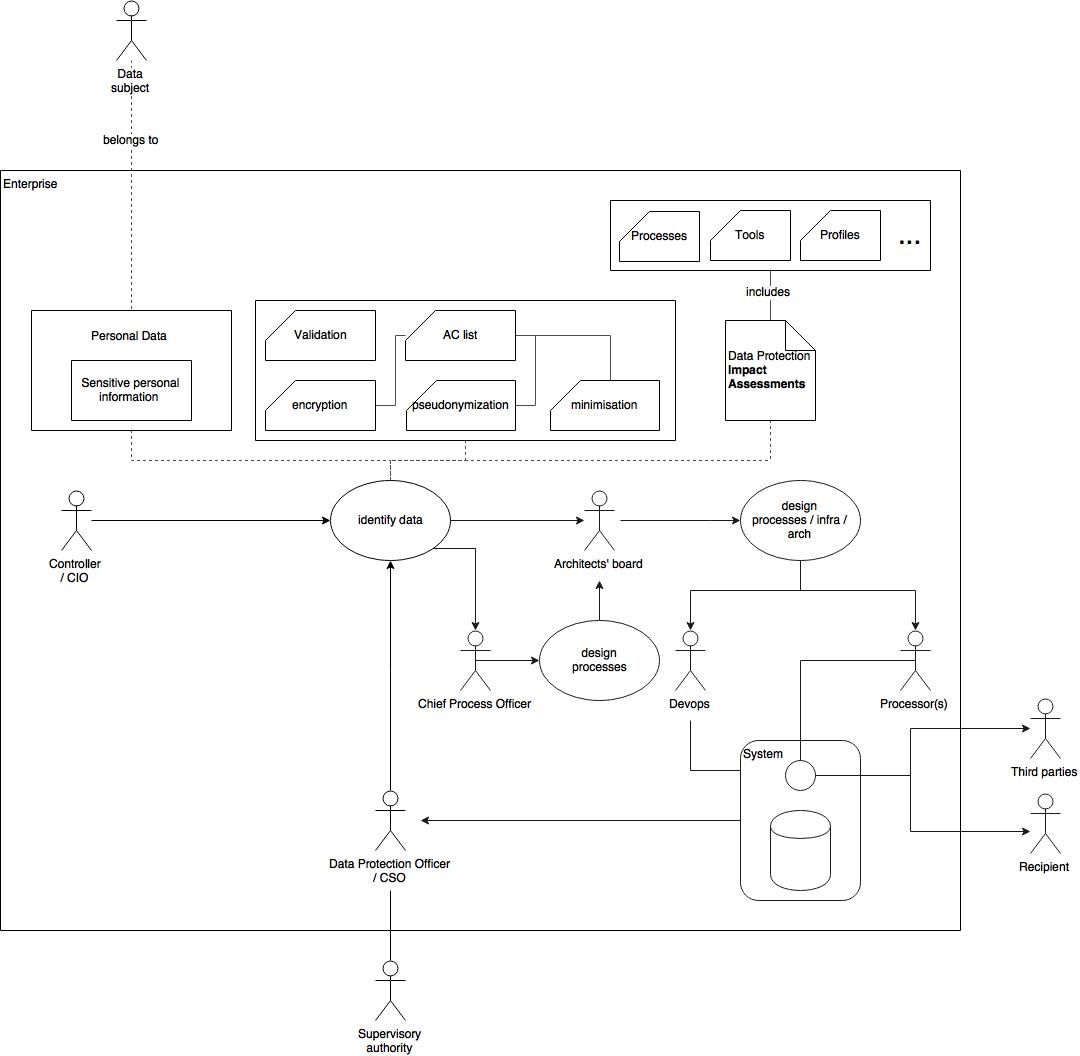
To clarify the new roles of GDPR using the definitions of Oracle:
- Data Subject: A person who can be identified directly or indirectly by means of an identifier
- Personal Data: Any personal information, including sensitive personal information, relating to a Data Subject
- Controller: A natural or legal person, public authority, agency or any other body which alone or jointly with others determines the purposes and means of the processing of personal data
- Data Protection Officer: An individual working for a Controller and/or a Processor with extensive knowledge of the data privacy laws and standards. Can be a Chief Security Officer (CSO) or a Security Administrator.
- Processor: A natural or legal person, agency or any other body which processes Personal Data on behalf of the Controller. For example, a developer, a tester, or an analyst.
- Recipient: A natural or legal person, agency or any other body to whom the personal data is disclosed. For example, an individual, a tax consultant, an insurance agent, or an agency.
- Third party: Any natural or legal person, agency or any other body other than the Data Subject, the Controller, the Processor and the persons who, under the direct authority of the Controller or the Processor, are authorized to process the data. For example, partners or subcontractors.
- Supervisory Authority: An independent public authority established by a Member State (known as the National Data Protection Authority under the current EU Data Protection Directive), or auditing agency.
What is sensitive data?
- racial or ethnic origin
- political opinions
- religious or philosophical beliefs
- trade union membership
- data concerning health or sex life and sexual orientation
- genetic data (new); and
- biometric data where processed to uniquely identify a person (new).
Let’s crack into it before it feels complex. It is fairly pure actually:
The Controller (CO) should bring the business cases and intel and - with the key assistance of the Data Protection Officer - has to define the Impact assessment documents identifying high risks to the privacy rights of individuals when processing their personal data.
The role of DPO can be seen as the enforcer of data protection standard at all levels and processes. The CO and the DPO also crystallise the processes, the tools, the responsibilities and technical requirements for all decision makers on different departments. At the end of the flow the dev / devops teams will necessarily adapt to these new regulations and flows.
As I mentioned in my initial summary, GDPR equally protects data from outer and inner threats: specifically, the GDPR defines the database containing personal data as “physically separated”. This means that different roles are allowed to see very different subset or content from the sensitive dataset.
Linger long enough on the significance of these sentences and you’ll start to appreciate why GDPR represents such a big change for IT. Really sensitive data cannot be read by developers, project owners or even by the CTO. Encryption, minimisation and access control on database / API levels are in play to protect data.
In our case study example, developers lost their precious “admin” access to the database, and were allowed to access data only through an API enforcing the AC defined by the Controller. Devops gurus also lost their ability to touch and alter sensitive things.
This is the reality when the “I mean no harm” or “I would never compromise data” oaths no longer cut the mustard. Let’s not forget that data subjects have the right (soon to be hardened in EU law) to learn what happened with their data. Who had access to it? Who enabled access? These considerations require companies to involve legal experts in the creation of impact assessment documents. Of course, company structure and level of GDPR impact vary among companies, and as already mentioned, legal and technical doors can be found to ease the semantic gravity of the standard …I do not want to disseminate generic sentences which can be interpreted depending on which way the wind blows.
To conclude our case study example: we introduced a docker-based solution which provided role-controlled API-level access to personal data following the specification of the schema defined by the impact analysis. It was fairly easy to deploy and scale: some code had to be changed in the legacy system to manage the 2 sources of data and follow the data-flow defined by the Controller. To change the data management layer sounds hard and deep, but a well-defined realisation plan can really minimise the pain. Three environments (int, qa, prod) ensured that developers were able to test smoothly and that the cultural transition was free of awkward bumps.
Hopefully this provides some immediate answers to the initial practical questions regarding requirement and meeting that requirement. This leaves one final question, one which I have been asked many times: why should we bother to adopt GDPR now, while some pieces are still missing and unclear?
My answer to this question is simple: adoption takes time and clearly involves a significant change in thinking and development culture. Better to be ahead of the curve.
Feel free to share your thoughts in comments below, I am willing to exchange thoughts with you.
If you consider to start a new project soon or to move your stack to NodeJS and do not mind some support and consulting, please let us know.
We are open for business at NLV8 Technologies.